Machine learning in computational biology
ENSAE
Spring 2013
Modern technologies like DNA microarrays or high-throughput sequencing are revolutionising biology and medical research. By allowing the collection of large amounts of measures at the molecular level on living organisms, they pave the way to a quantitative and rationale analysis of biological systems. Unsurprisingly, statistics and machine learning play an important role in this revolution. By processing large collections of datasets, they allow to extract new biological knowledge and infer predictive models.
The goal of this course is to present a few modern statistical learning techniques, and to touch upon a selected panel of applications in computational and systems biology. We will study in particular support vector machines (SVM) and kernels, as well as feature selection techniques including lasso regression. Applications include protein annotation, virtual screening in drug design, prognostic and predictive models for personalised medicine in oncology, and gene network inference in systems biology.
Schedule
| Date | Morning (11h-13h) | Afternoon (13h-15h) |
| Friday February 22, 2013 | Introduction, SVM (slides 1-53) | Kernels (slides 54-81) |
| Friday March 1, 2013 | String kernels, protein classification | String kernels |
| Friday March 29, 2013 | Graph kernels, virtual screening | |
| Friday April 19, 2013 | (8h30-10h30) Feature selection | (11h-13h)Diagnosis, prognosis |
| Friday April 26, 2013 | Structured feature selection | |
Project
We have collected gene expression levels for 4654 genes on 184 early-stage breast cancer samples: xtrain.txt (each row is a gene, each column a sample). After surgical removal of the tumour, some unfortunately relapsed within 5 years (label=+1), while other did not (label=-1). The labels of the the 184 samples are available in the file ytrain.txt.
- Propose and test different techniques to predict the relapse from gene expression data. Check the effect of parameters, estimate the performance.
- Make a prediction of relapse for the following 92 samples: xtest.txt. You should send me a file with 92 lines, each line containing a score which should be large if you think the corresponding sample has label +1 (relapse), small otherwise.
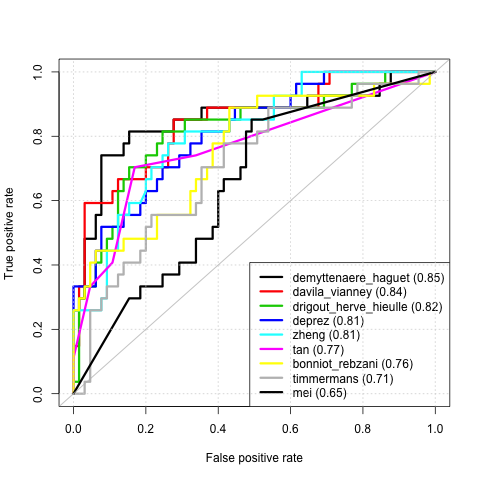
Please send report and prediction to jean-philippe.vert@mines.org before April 26, 10am. The predictions will be scored in terms of area under the ROC curve (AUC).
Practical sessions
Prerequisites
The practical sessions require the following free softwares:
P0: R basics
P1: SVM and kernel methods basics
- Goal: learn and manipulate SVM and kernel PCA, understand how they work on simple data, play with kernels and parameters.
- Application: cancer diagnosis from gene expression data.
- Notes
- Useful R functions
- Code
P2: Using your own kernels
- Goal: Use precomputed kernels, and define your own kernels.
- Notes
- Code
P3: Classification of sequences with string kernels
- Goal: understand and test a few string kernels, for classification of protein and DNA sequences
- Notes
- Code
P4: Reconstruction of regulatory networks from expression
P5: Reconstruction of PPI and metabolic networks
- Goal: understand and test several methods for the prediction of protein-protein interactions and edges in the metabolic network.
- ppimetabo.tar.gz: yeast datasets (PPI and metabolic networks)
- Notes
- Code
Back to my homepage